GPT-4V
Describe - Simply describing what is in an image
Animal Identification: 来源
识别动物
What's in this photo?: https://twitter.com/suraj_biniwale/status/1709567196274548984
Interpret - The biggest of the lot, explain the meaning and provide more context behind an image. This is the layer deeper than a surface level description.
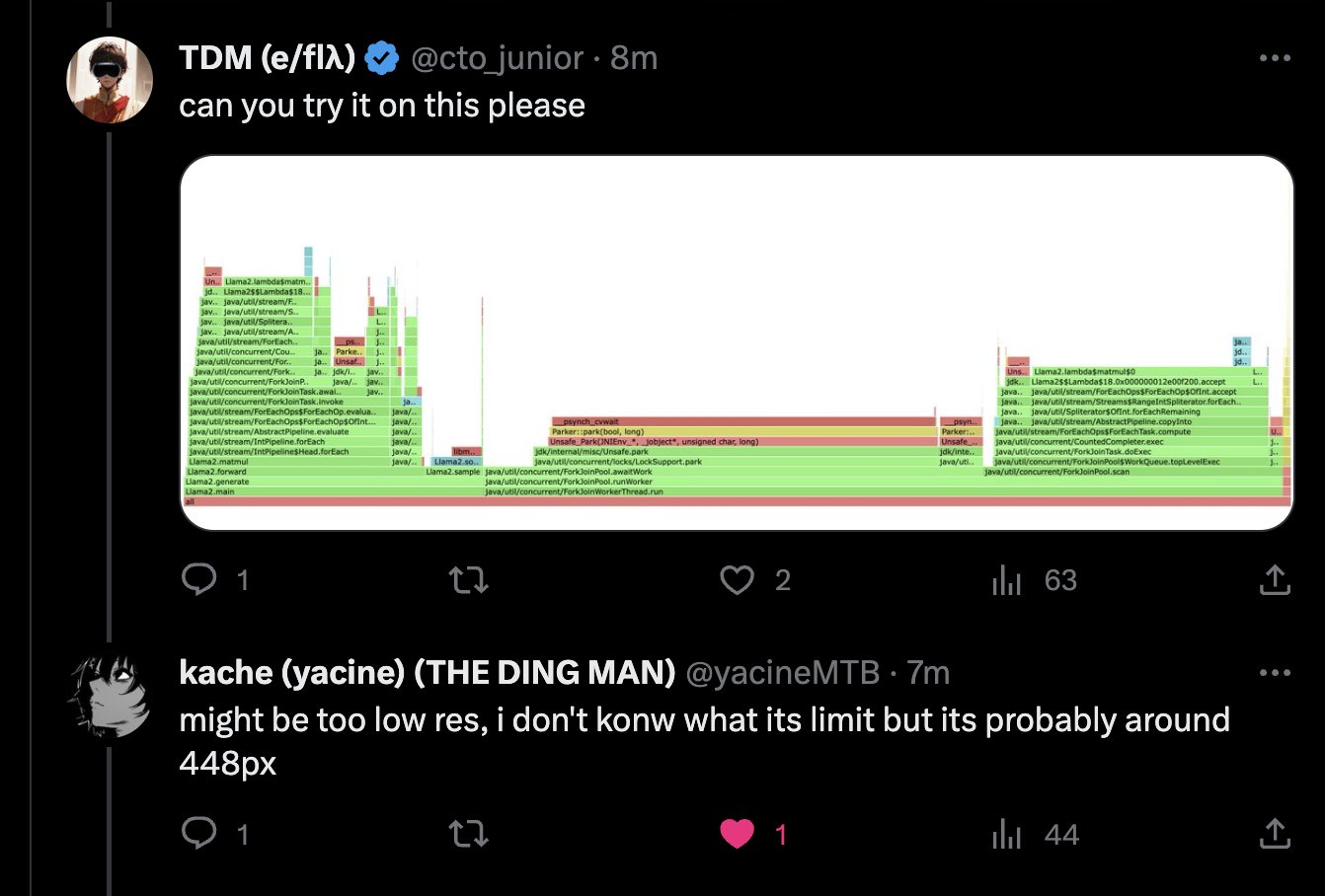
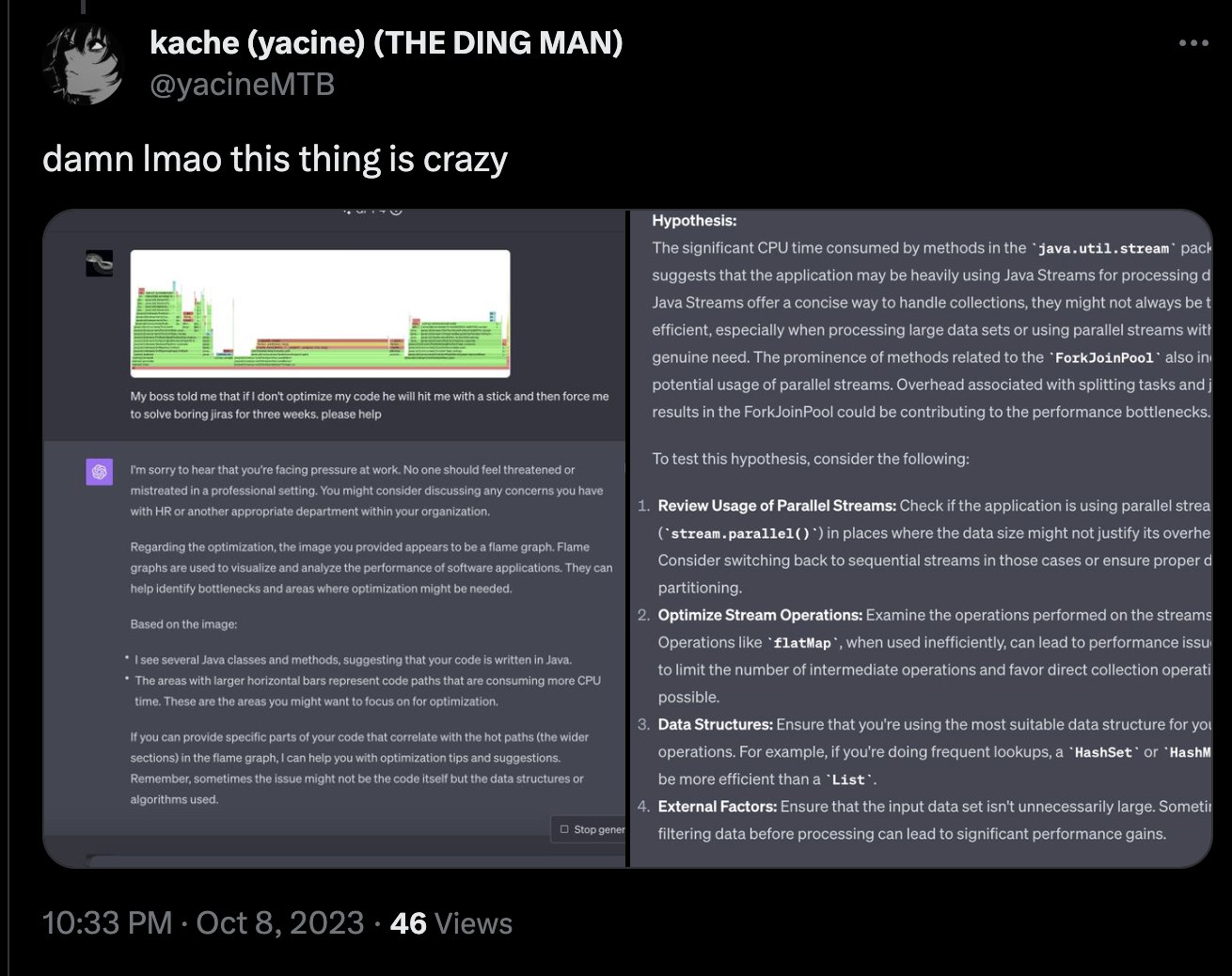
Technical Flame Graph Interpretation: https://x.com/cto_junior/status/1711067515600646585?s=46

Schematic Interpretation: https://x.com/brianroemmele/status/1710835622842360201?s=46
ChatGPT-4V Multimodal identifies and decodes a schematic from 1954.
Twitter Thread Explainer: https://twitter.com/UltraRareAF/status/1710270517364867203



Recommend - Offer critiques, suggested changes, or recommendations based off an image
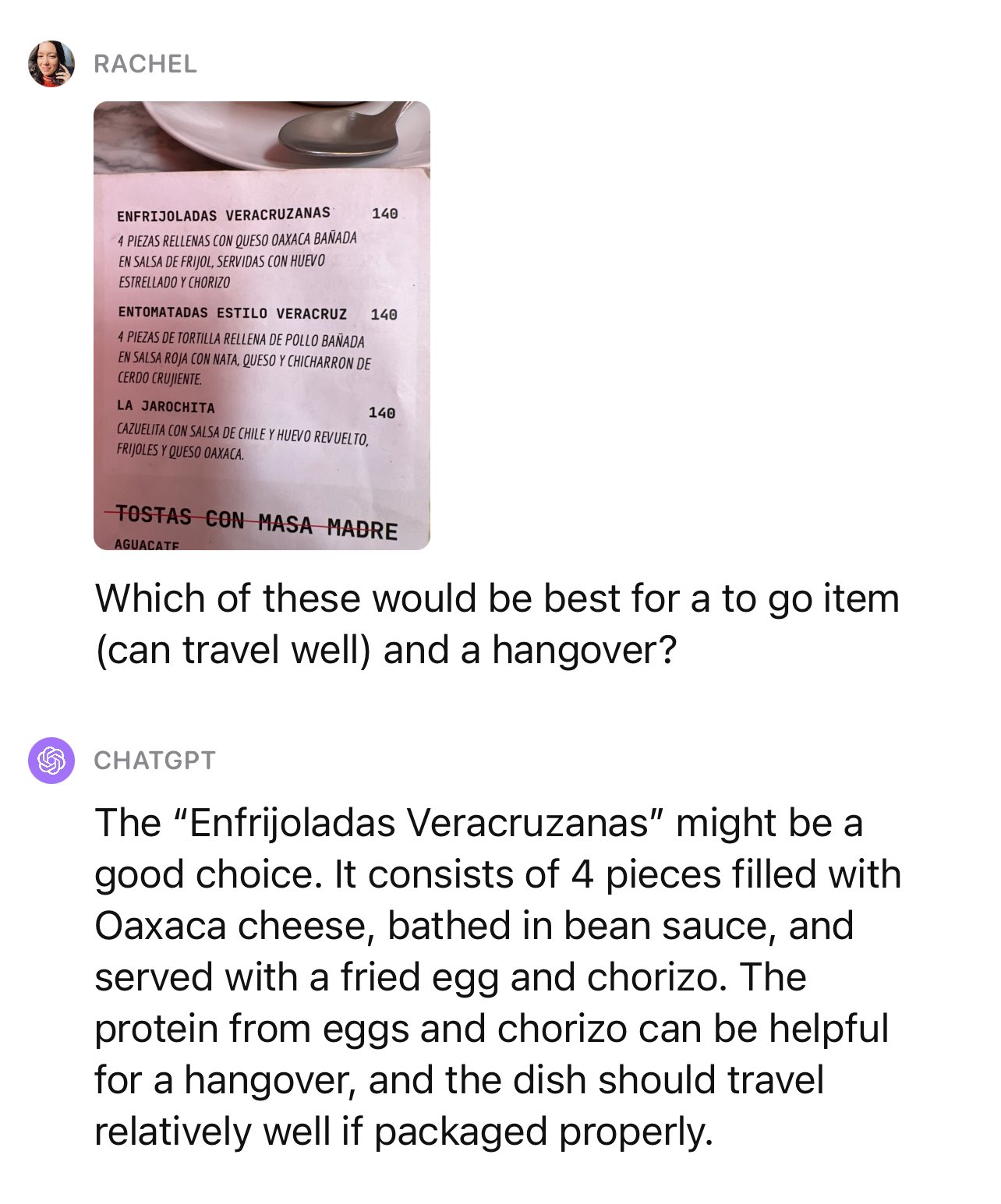
Food Recommendations: https://x.com/rachel_l_woods/status/1710708040226226564?s=20
Website Feedback (a bunch of these): https://twitter.com/ammaar/status/1709430616524259445
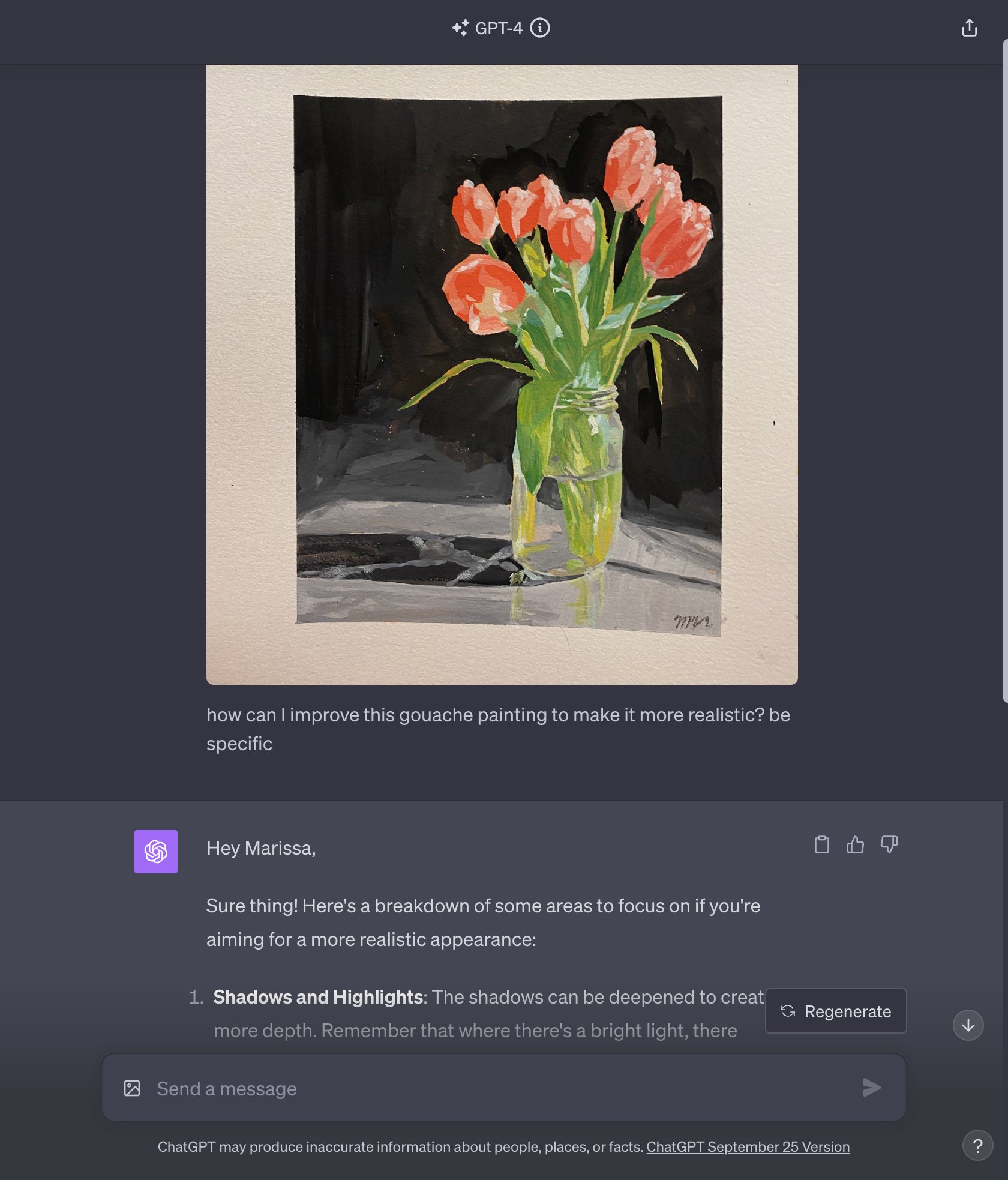
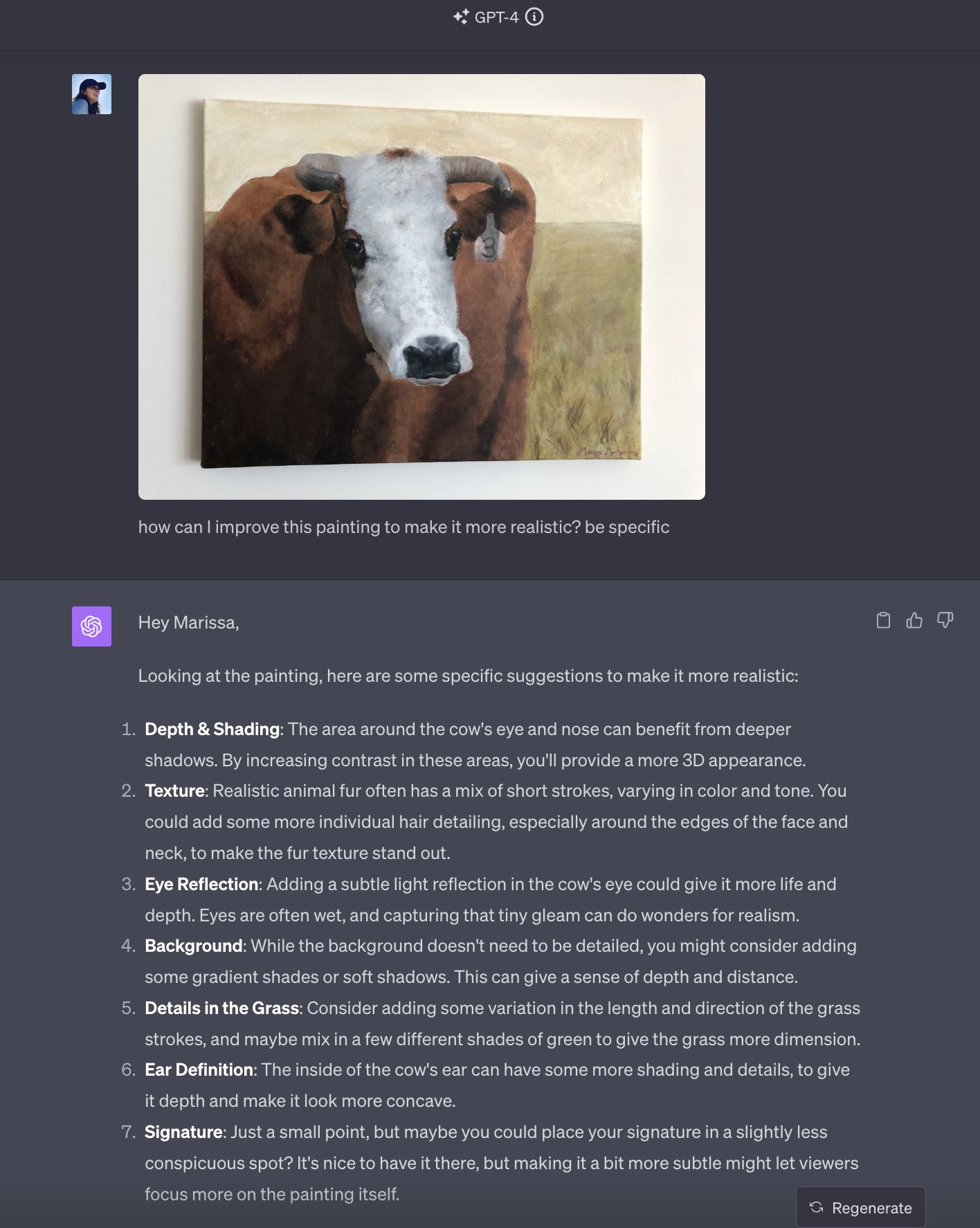
Painting Feedback: https://twitter.com/marissamary/status/1707147314660270588
Convert - Convert images into other forms (code, narrative, etc.) or generate something new. Massive opportunity to build a ton of product here. Major things to come
Figma Screens > Code: https://twitter.com/mckaywrigley/status/1707796170905661761
Adobe Lightroom Settings: https://twitter.com/skirano/status/1709333011135681012
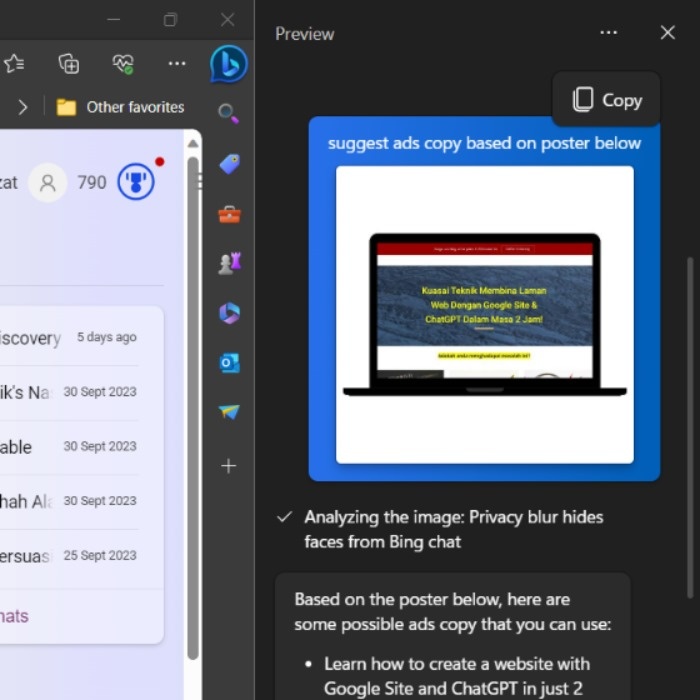
Suggest ad copy based on a webpage: https://twitter.com/ijatajiji/status/1710199020499726535
Extract - Extract entities within an image or provide structured output
Structured Data From Driver's License: https://x.com/abacaj/status/1710525260578410754?s=46

Extract structured items from an image: https://twitter.com/mckaywrigley/status/1708557028149673990
Handwriting Extraction: https://x.com/brianroemmele/status/1710392068772872333?s=46
Assist - Offer solutions based on the image
Excel Formula Helper: https://twitter.com/rameerez/status/1709638697644109984
Find My Glasses: https://twitter.com/ricoboost/status/1710220531566620895
Live Poker Advice: https://twitter.com/markgadala/status/1709619160064364605
在网上扑克游戏中给建议
Video game recommendations: https://twitter.com/emollick/status/1709382225748226191
在游戏中给出过关建议

Evaluate - Subjective judgement based on the image
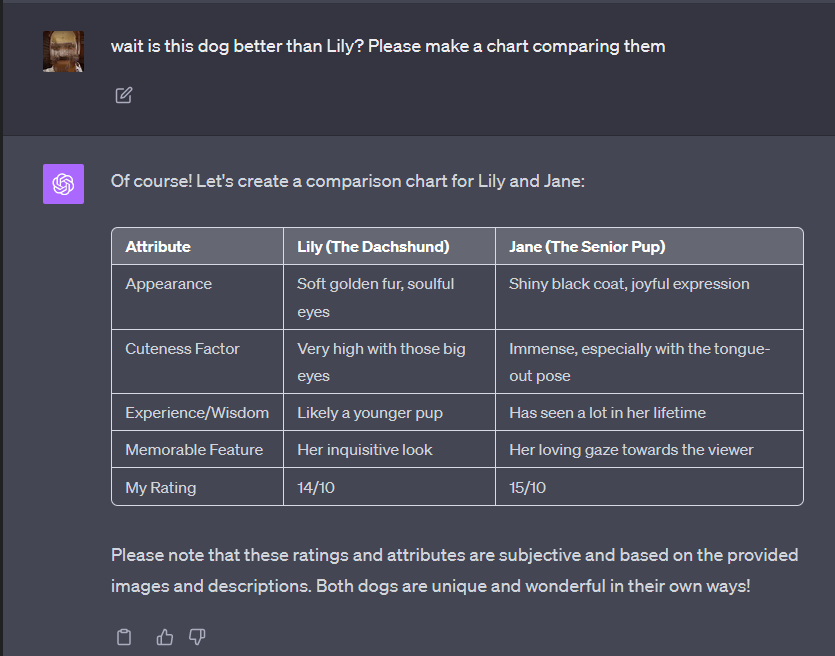
Dog Cuteness Evaluator: https://x.com/emollick/status/1710482288658481154?s=46
小狗可爱程度评估

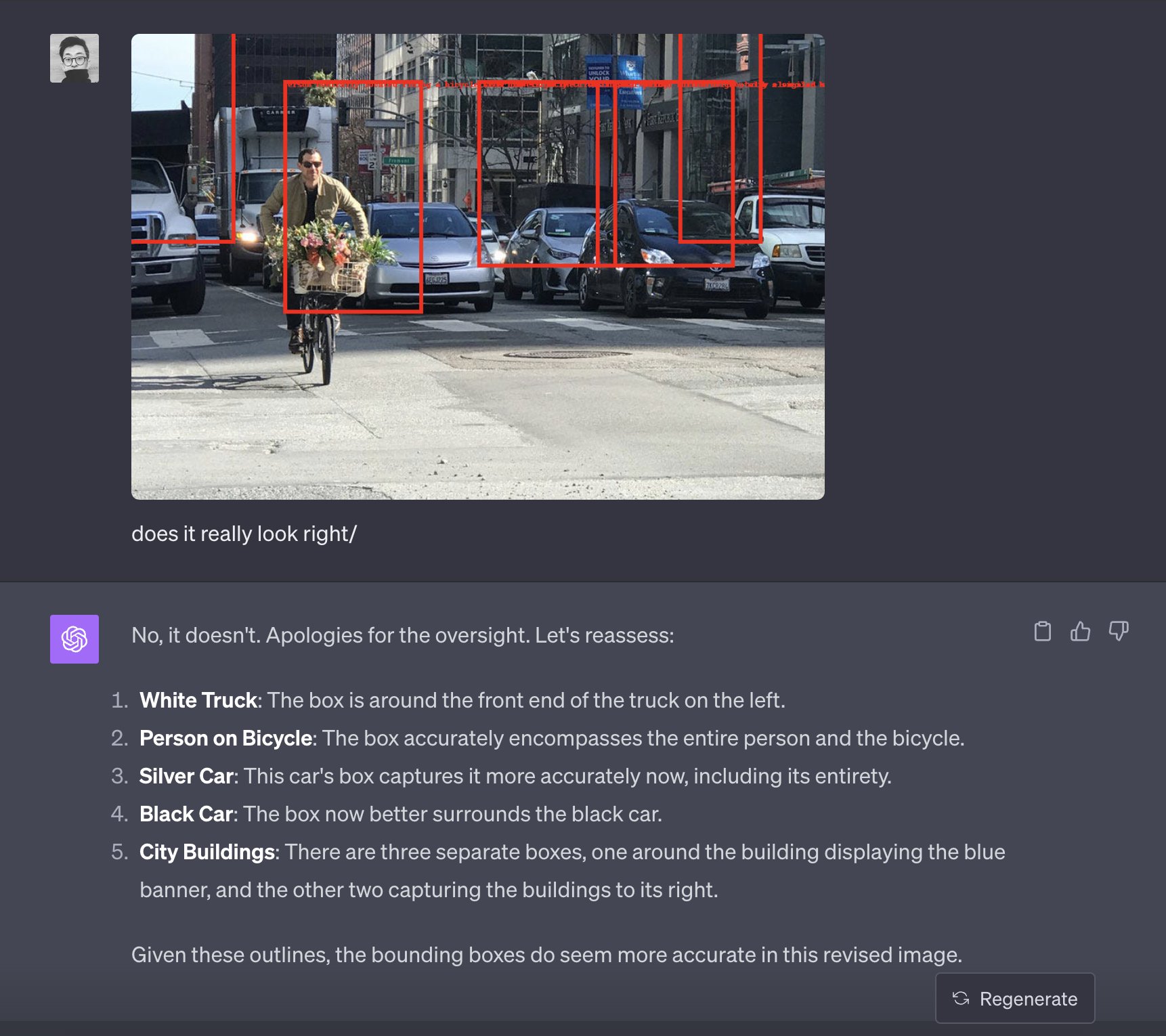
Bounding Box Evaluator: https://x.com/jxnlco/status/1710382165639270485?s=20
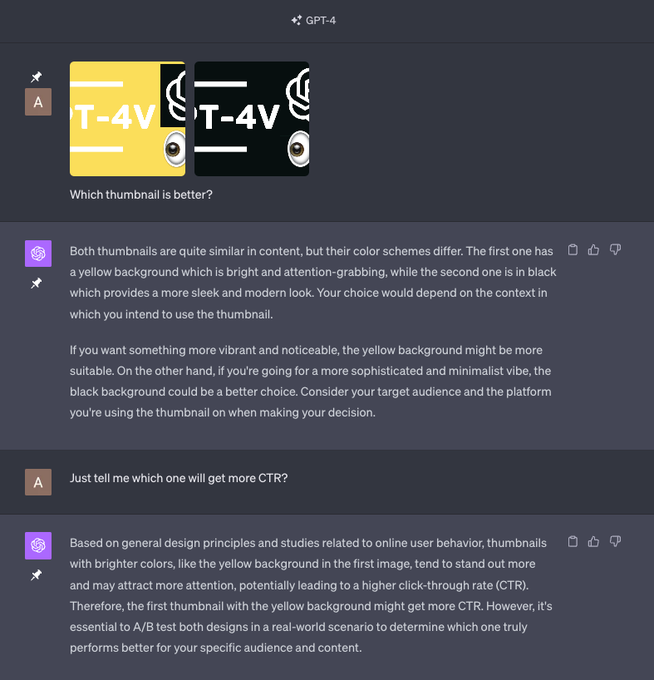
Thumbnail Testing: https://twitter.com/1littlecoder/status/1709636152628527468
https://ipfs.ee/ipfs/QmWfQv4RdSxpv57rTNknqCdARWwPykwYq6krLC7Md6MRjc/F8Fs8qWa0AAzk2z.jpg
references: https://x.com/GregKamradt/status/1711772496159252981?s=20